Introduction
Logistic Regression is a statistical method used for binary classification problems, where the goal is to predict the probability of an event occurring or not. It is a popular algorithm in machine learning, particularly in the field of supervised learning. In this blog post, we will explore the fundamentals of logistic regression and how it can be used to solve binary classification problems. We will also provide Python code examples to help you understand and implement this powerful algorithm in your own projects. Whether you’re new to machine learning or an experienced practitioner, this post will provide valuable insights into logistic regression and its applications. So, let’s dive in!
Use Cases for Logistic Regression for Binary Classification
• Logistic Regression is commonly used in the field of medical research to predict the likelihood of a patient developing a certain disease or condition. For example, a logistic regression model could be built using patient data such as age, gender, family history, and lifestyle factors to predict whether or not a patient is at high risk for developing heart disease.
• In the field of marketing, logistic regression can be used to predict customer behavior, such as whether or not they are likely to purchase a certain product. This information can then be used to target specific customers with personalized marketing campaigns.
• In finance, logistic regression can be used to predict the likelihood of default on loans or credit cards. By analyzing customer data such as income, credit score, and payment history, banks and other financial institutions can use logistic regression models to identify high-risk customers and take appropriate measures to minimize their losses.
• Logistic Regression is also widely used in the field of image recognition and computer vision. For example, it can be used to classify images based on their content, such as identifying whether an image contains a cat or a dog.
• In the field of fraud detection, logistic regression can be used to identify fraudulent transactions based on patterns in customer data such as transaction amounts, locations, and times. This information can then be used to flag suspicious transactions for further investigation.
• Logistic Regression can also be used in sports analytics to predict the outcome of games or matches. By analyzing historical data such as team performance metrics and player statistics, logistic regression models can help coaches and analysts make more informed decisions about game strategy and player selection.
How Logistic Regression for Binary Classification Works
Logistic Regression is a statistical method used for binary classification problems. In binary classification problems, we have a dataset with two possible outcomes such as yes or no, true or false, etc. The goal of logistic regression is to determine the relationship between the input variables and the output variable.
The logistic regression algorithm works by making a prediction using a linear combination of the input variables. This linear combination is then transformed using the sigmoid function which maps any real number to a value between 0 and 1. The sigmoid function can be represented as follows:

Where x is the input variable and y is the output variable.
In logistic regression, we use a cost function called the cross-entropy loss function to measure how well our model performs. The cross-entropy loss function can be represented as follows:
L(y, \hat{y}) = -\frac{1}{n}\sum_{i=1}^{n}[y_i \log{\hat{y_i}} + (1-y_i)\log{(1-\hat{y_i})}]In this equation, y is the vector of true labels, y_hat is the vector of predicted probabilities, n is the number of data points, and log is the natural logarithm.
The first term inside the summation calculates the contribution of the true positive examples to the loss, while the second term calculates the contribution of the true negative examples to the loss. The overall loss is the average of these individual losses, multiplied by -1.
The goal of logistic regression is to minimize this cost function by adjusting the weights and biases of our model using an optimization algorithm such as gradient descent. Once we have trained our model, we can use it to make predictions on new data by simply plugging in the values of the input variables into our model.
Here’s an example of a full manual implementation of logistic regression in Python:
import numpy as np
class LogisticRegression:
def __init__(self, learning_rate=0.01, num_iterations=10000):
self.learning_rate = learning_rate
self.num_iterations = num_iterations
self.weights = None
self.bias = None
def fit(self, X, y):
# initialize weights and bias to zero
self.weights = np.zeros(X.shape[1])
self.bias = 0
# gradient descent
for i in range(self.num_iterations):
z = np.dot(X, self.weights) + self.bias
y_pred = self.sigmoid(z)
# calculate gradients
dw = (1 / X.shape[0]) * np.dot(X.T, (y_pred - y))
db = (1 / X.shape[0]) * np.sum(y_pred - y)
# update weights and bias
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
def predict(self, X):
z = np.dot(X, self.weights) + self.bias
y_pred = self.sigmoid(z)
return np.round(y_pred)
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
In the above code, we define a LogisticRegression class with methods for fitting the model to the training data and making predictions on new data. The fit method uses gradient descent to adjust the weights and bias of our model to minimize the cross-entropy loss function. The predict method takes in new data and returns the predicted labels using our trained model.
Logistic Regression for Binary Classification Python Example
Let’s start with a brief introduction to logistic regression.
Logistic regression is a statistical method used to analyze the relationship between a dependent variable (usually binary) and one or more independent variables. It is commonly used for binary classification problems, where the goal is to predict the class of an observation based on its features.
In this example, we will be using the famous Iris dataset from scikit-learn. We will be performing binary classification on this dataset by predicting whether a flower is Iris Setosa or not based on its sepal length and width.
First, let’s import the necessary libraries and load the dataset:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :2]
y = (iris.target == 0).astype(int)
Here, we are using only the first two features (sepal length and width) of the Iris dataset. We are also converting the target variable into a binary variable by checking if it equals 0 (Iris Setosa) and then casting it to an integer.
Next, let’s visualize the data to get a better understanding of it:
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
This code plots a scatter plot of sepal length against sepal width, with different colors representing different classes. Here’s what it looks like:

Now that we have visualized our data, let’s move on to building our logistic regression model. We will be using scikit-learn’s LogisticRegression class:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X, y)
Here, we are fitting our model to the data. We can now use this model to make predictions on new data:
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
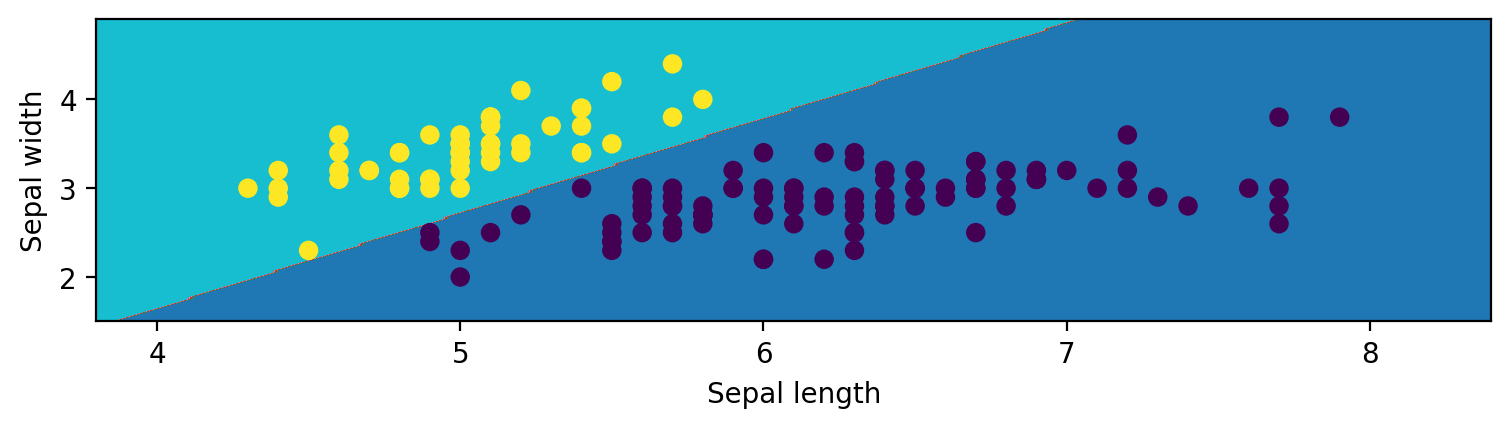
This code creates a meshgrid of points that covers the entire range of our data (with a step size of 0.02). We then use our trained model to predict the class of each point in the meshgrid and plot it as a contour plot. We also plot the original data points on top of this plot.
Here’s what the final output looks like:

As you can see, our logistic regression model does a good job of separating Iris Setosa from the other two classes based on sepal length and width.
That’s it for this example! Hopefully you now have a better understanding of how logistic regression works and how to implement it in Python using scikit-learn.
Pros of Logistic Regression for Binary Classification
Let’s discuss some advantages of Logistic Regression.
• Logistic Regression is a simple yet effective algorithm for binary classification. It can be used to predict the probability of a binary outcome given a set of input variables.
• One of the main advantages of Logistic Regression is its interpretability. The model coefficients can be easily interpreted as the effect of each input variable on the predicted probability. This makes it easy to understand the relationship between the input variables and the output.
• Another advantage of Logistic Regression is that it is computationally efficient and can handle large datasets with ease. It uses gradient descent optimization to minimize the cost function, which makes it very fast and scalable.
• Logistic Regression also performs well in situations where there is a linear relationship between the input variables and the output. In such cases, it can achieve high accuracy with relatively few input variables.
• Finally, Logistic Regression can handle both continuous and categorical input variables. It does this by using dummy variables to represent categorical variables, which allows it to capture non-linear relationships between the input variables and the output.
Cons of Logistic Regression for Binary Classification
Now let’s quickly go over some disadvantages.
• Logistic Regression can be prone to overfitting when dealing with complex data sets. This means that the model may perform well on the training data, but will not generalize well to new, unseen data.
• Logistic Regression assumes that there is a linear relationship between the independent variables and the log odds of the dependent variable. If this assumption is not met, the model may not perform well.
• Logistic Regression requires that the observations are independent of each other. If there is any correlation between the observations, such as in time series data, logistic regression may not be appropriate.
• Logistic Regression can be sensitive to outliers in the data. Outliers can have a large impact on the estimated coefficients, which can lead to poor performance of the model.
• Logistic Regression cannot handle missing values in the data. If there are missing values, they must be imputed or removed from the analysis. This can be problematic if there is a large amount of missing data, or if the “missingness” is not random.
Conclusion
In conclusion, logistic regression is a powerful tool for binary classification problems. It is a simple yet effective algorithm that can be used to predict the probability of an event occurring. By modeling the relationship between the input variables and the output variable, logistic regression can help us understand which variables are most important in predicting the outcome. With its ability to handle both linear and non-linear relationships, logistic regression is widely used in various fields such as finance, healthcare, marketing, and more. However, it is important to keep in mind that logistic regression assumes that the data is linearly separable and may not perform well on highly non-linear datasets. Overall, logistic regression is a valuable tool to have in your machine learning toolkit when dealing with binary classification problems.
Want to learn more about Data Science? Consider downloading our guide below:

Your FREE Guide to Become a Data Scientist
Discover the path to becoming a data scientist with our comprehensive FREE guide! Unlock your potential in this in-demand field and access valuable resources to kickstart your journey.
Don’t wait, download now and transform your career!



