
Cross-validation is a powerful technique for assessing the performance of machine learning models. It allows you to make better predictions by training and evaluating the model on different subsets of the data. In this blog post, we’ll dive deep into the cross_validate function in the Scikit-Learn library, which allows for efficient cross-validation in Python. We’ll cover the following topics:
Table of Contents
- Introduction to Cross-Validation
- Getting Started with Scikit-Learn and cross_validate
- Customizing the cross_validate Function
- Working with Different Types of Models
- Handling Imbalanced Data with cross_validate
- Nested Cross-Validation for Model Selection
- Conclusion
1. Introduction to Cross-Validation
Cross-validation is a statistical method for evaluating the performance of machine learning models. It involves splitting the dataset into two parts: a training set and a validation set. The model is trained on the training set, and its performance is evaluated on the validation set.
It is not recommended to learn the parameters of a prediction function and then test it on the same data. This is because a model that simply repeats the labels of the samples it has seen before would have a perfect score, but it would not be able to predict anything useful on new data. This is called overfitting. To prevent this, it is standard practice in supervised machine learning experiments to reserve a portion of available data as a test set (X_test, y_test). It’s worth noting that the term “experiment” here does not only apply to academic settings since even commercial machine learning typically begins experimentally. A typical cross-validation workflow in model training involves finding the best parameters through grid search techniques.
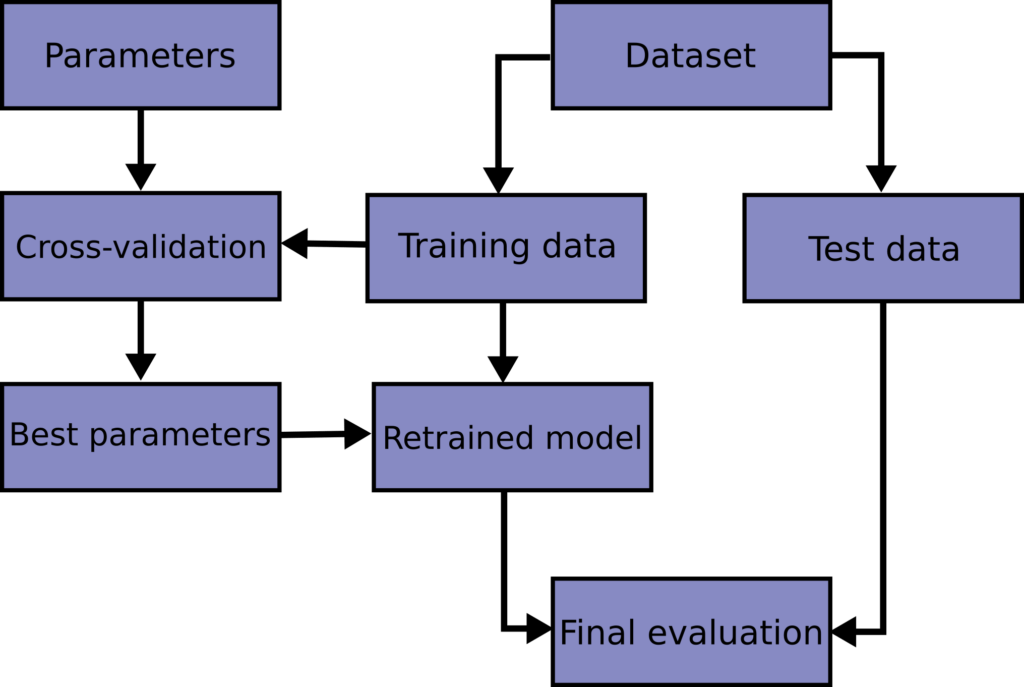
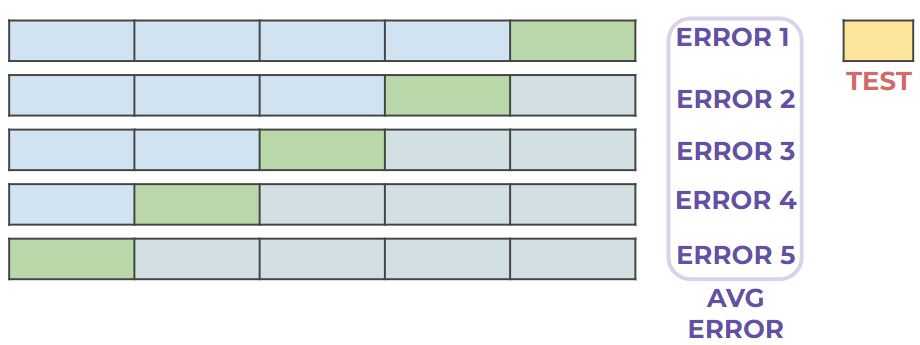
The most common form of cross-validation is k-fold cross-validation. The basic idea behind K-fold cross-validation is to split the dataset into K equal parts, where K is a positive integer. Then, we train the model on K-1 parts and test it on the remaining one. This process is repeated K times, with each of the K parts serving as the testing set exactly once.
The steps for implementing K-fold cross-validation are as follows:
- Split the dataset into K equally sized partitions or “folds”.
- For each of the K folds, train the model on the K-1 folds and evaluate it on the remaining fold.
- Record the evaluation metric (such as accuracy, precision, or recall) for each fold.
- Compute the average performance across all K folds.
The main advantage of K-fold cross-validation is that it allows us to obtain a more accurate estimate of a model’s performance, as it ensures that each data point in the dataset is used for both training and testing. This is particularly useful when the dataset is small, as it allows us to make the most of the available data. Additionally, K-fold cross-validation can help prevent overfitting by providing a more representative estimate of the model’s performance on new, unseen data.
We can see the process in the diagram below:
2. Getting Started with Scikit-Learn and cross_validate
Scikit-Learn is a popular Python library for machine learning that provides simple and efficient tools for data mining and data analysis. The cross_validate function is part of the model_selection module and allows you to perform k-fold cross-validation with ease. Let’s start by importing the necessary libraries and loading a sample dataset:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_validate
from sklearn.linear_model import LogisticRegression
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Create a logistic regression model
model = LogisticRegression(max_iter=1000)
Now we can use the cross_validate function to perform 5-fold cross-validation on our dataset:
# Perform 5-fold cross-validation
cv_results = cross_validate(model, X, y, cv=5)
# Print the results
print(cv_results)
The cross_validate function returns a dictionary containing the training and validation scores for each fold, as well as the fit and score times. For example, the output might look like this:
{'fit_time': array([0.035, 0.031, 0.028, 0.027, 0.027]),
'score_time': array([0.001, 0.001, 0.001, 0.001, 0.001]),
'test_score': array([0.967, 1. , 0.933, 0.967, 1. ])}
3. Customizing the cross_validate Function
The cross_validate function offers many options for customization, including the ability to specify the scoring metric, return the training scores, and use different cross-validation strategies.
3.1 Specifying the Scoring Metric
By default, the cross_validate function uses the default scoring metric for the estimator (e.g., accuracy for classification models). You can specify one or more custom scoring metrics using the scoring parameter. Here’s an example using precision, recall, and F1-score:
from sklearn.metrics import make_scorer, precision_score, recall_score, f1_score
# Define custom scoring metrics
scoring = {
'precision': make_scorer(precision_score, average='weighted'),
'recall': make_scorer(recall_score, average='weighted'),
'f1_score': make_scorer(f1_score, average='weighted')
}
# Perform 5-fold cross-validation with custom scoring metrics
cv_results = cross_validate(model, X, y, cv=5, scoring=scoring)
# Print the results
print(cv_results)
3.2 Returning Training Scores
By default, the cross_validate function only returns the validation scores. You can also return the training scores by setting the return_train_score parameter to True:
cv_results = cross_validate(model, X, y, cv=5, return_train_score=True)
print(cv_results)
4. Workingwith Different Types of Models
The cross_validate function works with any estimator that implements a fit and score method, which includes most models in Scikit-Learn. Here’s an example using a support vector machine (SVM) and a random forest classifier:
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
# Create an SVM model and a random forest model
svm = SVC(kernel='linear', C=1, random_state=42)
rf = RandomForestClassifier(n_estimators=100, random_state=42)
# Perform 5-fold cross-validation for both models
cv_results_svm = cross_validate(svm, X, y, cv=5)
cv_results_rf = cross_validate(rf, X, y, cv=5)
# Print the results
print("SVM:", cv_results_svm)
print("Random Forest:", cv_results_rf)
5. Handling Imbalanced Data with cross_validate
When dealing with imbalanced datasets, it’s important to use cross-validation strategies that maintain the class distribution in each fold. Scikit-Learn provides the StratifiedKFold class for this purpose. Here’s an example:
from sklearn.model_selection import StratifiedKFold
# Create a stratified k-fold cross-validator
stratified_cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# Perform 5-fold stratified cross-validation
cv_results = cross_validate(model, X, y, cv=stratified_cv)
# Print the results
print(cv_results)
6. Nested Cross-Validation for Model Selection
Nested cross-validation is a technique for model selection and hyperparameter tuning. It involves performing cross-validation on both the training and validation sets, which helps to avoid overfitting and selection bias. You can use the cross_validate function in a nested loop to perform nested cross-validation. Here’s an example using different values of the C parameter in a logistic regression model:
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
# Define the outer and inner cross-validation strategies
outer_cv = KFold(n_splits=5, shuffle=True, random_state=42)
inner_cv = KFold(n_splits=5, shuffle=True, random_state=42)
# Define the parameter grid
C_values = [0.001, 0.01, 0.1, 1, 10, 100]
# Nested cross-validation
outer_scores = []
for train_index, val_index in outer_cv.split(X, y):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]
best_score = 0
best_C = None
for C in C_values:
model = LogisticRegression(C=C, max_iter=1000)
inner_scores = cross_validate(model, X_train, y_train, cv=inner_cv, scoring='accuracy')['test_score']
score = np.mean(inner_scores)
if score > best_score:
best_score = score
best_C = C
# Train the model with the best C value on the outer training set
model = LogisticRegression(C=best_C, max_iter=1000)
model.fit(X_train, y_train)
val_score = accuracy_score(y_val, model.predict(X_val))
outer_scores.append(val_score)
# Print the average accuracy across the outer folds
print("Average accuracy:", np.mean(outer_scores))
7. Conclusion
In this blog post, we explored the cross_validate function in Scikit-Learn for performing cross-validation in Python. We covered how to use the function with different types of models, customize the scoring metrics, handle imbalanced data, and perform nested cross-validation for model selection. The cross_validate function is a powerful tool for assessing the performance of machine learning models and should be an essential part of your data science toolkit.
If you’re interested in learning more about becoming a Data Scientist, check out our free guide below:

Your FREE Guide to Become a Data Scientist
Discover the path to becoming a data scientist with our comprehensive FREE guide! Unlock your potential in this in-demand field and access valuable resources to kickstart your journey.
Don’t wait, download now and transform your career!



